Saat memodelkan data dunia nyata untuk analisis regresi, kami mengamati bahwa jarang terjadi persamaan model adalah persamaan linier yang menghasilkan grafik linier. Seringkali, persamaan model data dunia nyata melibatkan fungsi matematika dengan derajat yang lebih tinggi seperti eksponen 3 atau fungsi sin. Dalam skenario seperti itu, plot model memberikan kurva, bukan garis. Sasaran dari regresi linier dan non-linier adalah untuk menyesuaikan nilai parameter model untuk menemukan garis atau kurva yang paling dekat dengan data . Saat menemukan nilai-nilai ini kita akan dapat memperkirakan variabel respon dengan akurasi yang baik.
Dalam Least Square regression, kita akan membuat model regresi di mana jumlah kuadrat jarak vertikal dari titik yang berbeda dari kurva regresi diminimalkan. Biasanya dimulai dengan model yang ditentukan dan mengasumsikan beberapa nilai untuk koefisien. Kemudian menerapkan fungsi nls() dari R untuk mendapatkan nilai yang lebih akurat bersama dengan interval kepercayaan.
Sintaks dasar untuk membuat pengujian nonlinear least square di R adalah –
nls (formula, data, start)
Deskripsi :
formula adalah rumus model nonlinier yang meliputi variabel dan parameter.
data adalah kerangka data yang digunakan untuk mengevaluasi variabel dalam rumus.
start adalah daftar bernama atau vektor numerik bernama dari perkiraan awal.
Contoh
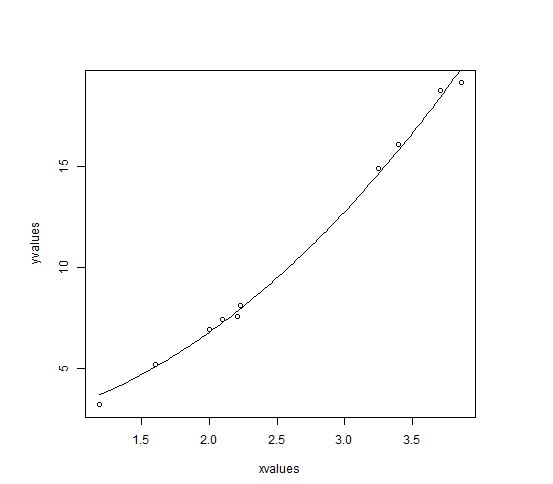
Kita akan mempertimbangkan model nonlinier dengan asumsi nilai awal koefisiennya. Selanjutnya kita akan melihat berapa interval kepercayaan dari nilai-nilai yang diasumsikan ini sehingga kita dapat menilai seberapa baik nilai-nilai ini masuk ke dalam model.
Jadi mari kita pertimbangkan persamaan di bawah ini :
a = b1*x^2+b2Mari kita asumsikan koefisien awal menjadi 1 dan 3 dan masukkan nilai-nilai ini ke dalam fungsi nls().
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21) yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58) # Beri nama file chart png(file = "nls.png") # Plot nilai-nilai ini. plot(xvalues,yvalues) # Ambil nilai yang diasumsikan dan cocokkan dengan model. model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3)) # Plot diagram dengan data baru dengan menyesuaikannya dengan prediksi dari 100 titik data. new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100)) lines(new.data$xvalues,predict(model,newdata = new.data)) # Simpan file. dev.off() # Dapatkan jumlah sisa kuadrat. print(sum(resid(model)^2)) # Dapatkan interval kepercayaan pada nilai koefisien yang dipilih. print(confint(model))
Output :
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484Dapat disimpulkan bahwa nilai b1 lebih mendekati 1 sedangkan nilai b2 lebih mendekati 2 dan bukan 3.
{kind=link}