Sebelum kita mulai, perlu diketahui bahwa ada versi lain yang umum digunakan dari Naive Bayes, yang disebut klasifikasi Gaussian Naive Bayes.
Sekarang bayangkan kita menerima Pesan Normal dari teman dan keluarga, dan kita juga menerima Spam (pesan yang tidak diinginkan yang biasanya penipuan atau iklan yang tidak diminta), dan kita ingin menyaring pesan Spam tersebut.
Jadi hal pertama yang kita lakukan adalah membuat grafik dari semua kata yang muncul di Pesan Normal dari teman dan keluarga.
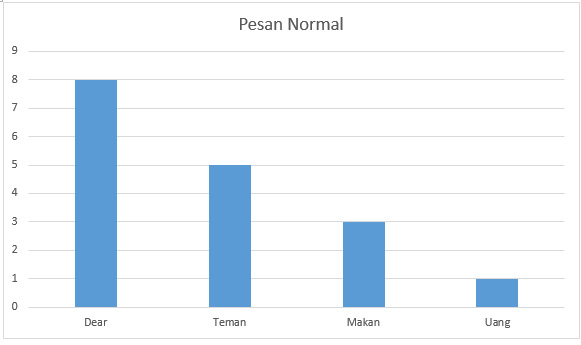
Kita dapat menggunakan grafik ini untuk menghitung probabilitas dengan melihat setiap kata dalam pesan Normal. Misalnya, probabilitas kita melihat kata “Dear” dibagi dengan jumlah total kata di semua pesan Normal dan itu memberi kita nilai 0,47.

Seperti hal berikutnya , probabilitas kita melihat kata “Teman” yang kita lihat di pesan Normal adalah 5 dibagi 17 (jumlah total kata di semua pesan Normal) dan itu memberi kita 0,29.

Selanjutnya, probabilitas kita melihat kata “Makan” yang diberikan bahwa kita melihatnya dalam pesan Normal adalah 0,18

dan probabilitas kita melihat kata “Uang”, mengingat bahwa itu ada dalam pesan Normal adalah 0,06.

Sekarang kita membuat grafik dari semua kata yang terjadi di Spam,

Dan kami menghitung probabilitas melihat kata “Dear” mengingat kami melihatnya di Spam, dan itu adalah 2, berapa kali kita melihat “Dear” di Spam dibagi 7, jumlah kata dalam Spam.

Selanjutnya, kami menghitung probabilitas kami melihat kata-kata yang tersisa, mengingat kita berada dalam Spam.



Karena kita telah menghitung probabilitas kata-kata terpisah, dan bukan probabilitas dari sesuatu yang kontinu, seperti berat atau tinggi, probabilitas ini juga disebut kemungkinan.
Saya menyebutkan ini karena beberapa tutorial mengatakan ini adalah probabilitas, dan yang lain mengatakan itu adalah kemungkinan. Dalam hal ini, istilah-istilah tersebut dapat dipertukarkan. jadi jangan dipikirkan, kita akan berbicara lebih banyak tentang probabilitas vs kemungkinan ketika kita berbicara tentang gaussian Naive Bayes.
Sekarang, bayangkan kita mendapat pesan baru yang mengatakan “Teman”. Dan kita ingin memutuskan apakah itu pesan Normal atau Spam. kita mulai dengan tebakan awal
tentang kemungkinan bahwa pesan apa pun, terlepas dari apa yang dikatakannya, adalah pesan Normal.
Tebakan dapat berupa probabilitas apa pun yang kita inginkan, tetapi perkiraan umum diperkirakan dari data latihan. Tebakan ini bisa berupa apa saja antara 0 dan 1, misalnya, karena 8 dari 12 pesan adalah pesan Normal, tebakan awal kita adalah 0,67.
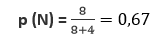
P (N): tebakan awal yang kita amati pesan Normal disebut probabilitas prior.
Sekarang kita mengalikan tebakan awal itu dengan probabilitas bahwa kata “Dear Teman” muncul dalam pesan Normal dengan rumus sebagai berikut:
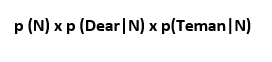
sekarang kita hanya memasukkan nilai yang kita kerjakan sebelumnya
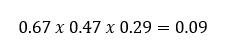
Kita dapat menganggap 0,09 sebagai skor yang didapat “Dear Teman” jika itu adalah pesan Normal. namun secara teknis dapat dituliskan sebagai berikut:
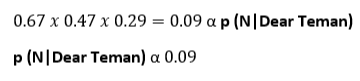
Sekarang, seperti yang kita lakukan sebelumnya, kita mulai dengan perkiraan awal tentang kemungkinan bahwa pesan apa pun, terlepas dari apa yang dikatakannya, adalah Spam.
Dan seperti sebelumnya, tebakan bisa berupa probabilitas yang kita inginkan, tetapi perkiraan umum diperkirakan dari data pelatihan. Dan karena 4 dari 12 pesan adalah Spam, perkiraan awal kita adalah 0,33.
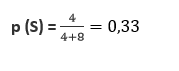
Sekarang kita mengalikan tebakan awal itu dengan probabilitas bahwa kata “Dear Teman” muncul dalam Spam.

sekarang kita hanya memasukkan nilai yang kita kerjakan sebelumnya. Kita bisa menganggap 0,01 sebagai skor yang diperoleh “Dear Teman” jika itu adalah Spam. namun secara teknis dapat dituliskan sebagai berikut:
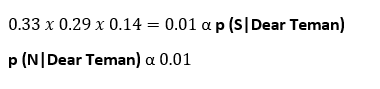
Dan karena skor yang kita dapatkan untuk pesan Normal 0,09 lebih besar dari skor yang kami gunakan untuk Spam 0,01, kita dapat memutuskan bahwa “Dear Teman” adalah pesan Normal.
mari kita lihat contoh yang sedikit lebih rumit. kali ini mari kita coba untuk mengklasifikasikan pesan ini.
Makan Uang Uang Uang Uang Uang
pesan ini memiliki kata Uang empat kali, dan karena melihat probabilitas kata Uang jauh lebih tinggi di spam (0,56) daripada di pesan Normal (0,06) maka tampaknya masuk akal untuk memprediksi bahwa pesan ini akan menjadi Spam.
Jadi mari kita lakukan matematika seperti sebelumnya
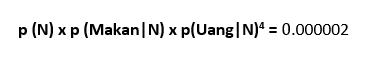
Namun ketika kami melakukan perhitungan yang sama untuk Spam, kami mendapatkan nilai 0.
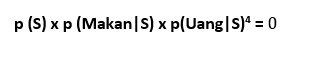
ini karena pobabilitas yang kita lihat Makan di Spam adalah 0, karena tidak ada dalam data latihan. Dengan kata lain, jika sebuah pesan berisi kata Makan, itu tidak akan diklasifikasikan sebagai Spam.
Dan itu berarti kita akan selalu mengklasifikasikan pesan dengan makan di dalamnya sebagai pesan Normal,entah berapa kali kita melihat kata Uang. Dan itu menjadi masalah, untuk mengatasi masalah ini, orang biasanya menambahkan 1 hitungan, untuk setiap kata dalam grafik.
Jumlah hitungan yang kita tambahkan ke setiap kata biasanya disebut dengan huruf yunani α (alpha). Dalam hal ini, α = 1, tapi kita bisa mengaturnya kedalam apapun.
bagaimanapun, dengan begitu ketika kita menghitung probabilitas dari mengamati setiap kata, kita tidak akan pernah mendapatkan 0. misalnya, probabilitas untuk melihat kata Makan, (jumlah ekstra yang kami tambahkan)
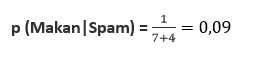
Menambahkan hitungan ke setiap kata tidak mengubah tebakan awal kita bahwa pesan itu Normal atau tebakan awal bahwa pesan adalah spam, karena menambahkan hitungan ke setiap kata tidak mengubah jumlah pesan di dataset latihan yang normal (8). sekarang kita menghitung skor untuk pesan ini.
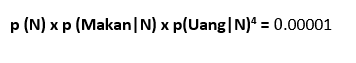
tetapi sekarang ketika kita melakukan perhitungan yang sama untuk spam kita mendapatkan nilai> 0
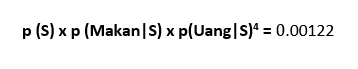
jadi, kami mengklasifikasikan pesan tersebut sebagai Spam.
Penutup
Sekarang mari kita bicara tentang mengapa Naive Bayes itu naif. Hal yang membuat Naive Bayes begitu naif adalah bahwa ia memperlakukan semua urutan kata dengan sama. Misalnya, skor pesan Normal untuk kalimat Dear Teman sama persis dengan skor untuk Teman Dear. dengan kata lain, terlepas dari bagaimana kata-kata tersebut disusun, kita pasti mendapatkan nilai 0,08.
Memperlakukan semua urutan kata secara sama sangat berbeda dari cara kita berkomunikasi. Setiap bahasa memiliki aturan tata bahasa dan frasa umum, tetapi Naive Bayes mengabaikan semua hal itu.
sebaliknya, Naive Bayes memperlakukan bahasa seperti sekantong penuh dengan kata-kata dan setiap pesan berisi beberapa kata secara acak. Naive Bayes mengabaikan semua aturan karena tidak mungkin melacak setiap frasa yang masuk akal dalam suatu bahasa.
Meskipun demikian, meskipun Naive Bayes adalah naif, performanya cenderung sangat baik saat memisahkan pesan Normal dari Spam. Dalam hal ini, kami akan mengatakan bahwa dengan mengabaikan hubungan antar kata, Naive Bayes memiliki Bias yang tinggi, tetapi karena bekerja dengan baik dalam praktiknya, Naive Bayes memiliki varian yang rendah.