Section Artikel
Evaluasi Model
Dalam Pembelajaran Mesin kita membuat model untuk memprediksi hasil dari peristiwa tertentu, seperti di bab sebelumnya di mana kita memperkirakan emisi CO2 mobil ketika mengetahui berat dan volume mesin.
Untuk mengukur apakah model tersebut cukup baik, kita dapat menggunakan metode yang disebut Train / Test.
Apa itu Train / Test
Train / Test adalah metode untuk mengukur akurasi model yang kita buat.
Disebut Train / Test karena kita membagi kumpulan data menjadi dua set: satu set pelatihan dan satu set pengujian.
80% untuk pelatihan, dan 20% untuk pengujian.
Anda melatih model menggunakan set pelatihan.
Anda menguji model menggunakan set pengujian.
Train model berarti membuat model.
Test model berarti menguji keakuratan model.
Mulai Dengan Set Data
Mulai dengan set data yang ingin diuji.
Kumpulan data ini menggambarkan 100 pelanggan di sebuah toko, dan kebiasaan berbelanja mereka.
Contoh:
import numpy import matplotlib.pyplot as plt numpy.random.seed(2) x = numpy.random.normal(3, 1, 100) y = numpy.random.normal(150, 40, 100) / x plt.scatter(x, y) plt.show()
Hasil:
Sumbu x mewakili jumlah menit sebelum melakukan pembelian.
Sumbu y mewakili jumlah uang yang dihabiskan untuk pembelian.
Bagi Menjadi Train / Test
Training set harus berupa pilihan acak 80% dari data asli.
Test Set harus 20% sisanya.
train_x = x [: 80]
train_y = y [: 80]
test_x = x [80:]
test_y = y [80:]
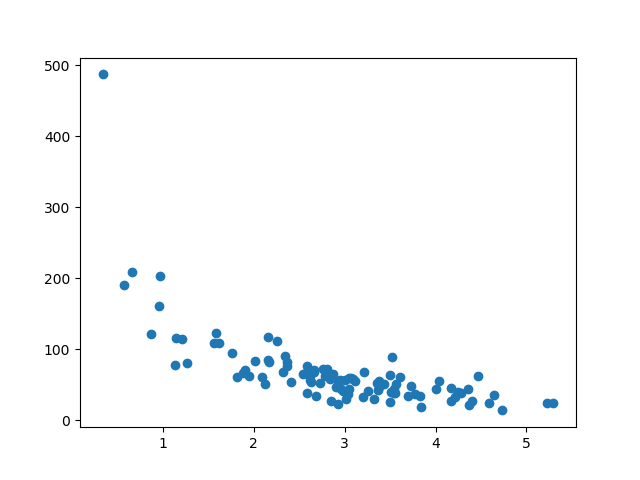
Tampilkan Training Set
Tampilkan plot scatter yang sama dengan training set.
Contoh:
import numpy import matplotlib.pyplot as plt numpy.random.seed(2) x = numpy.random.normal(3, 1, 100) y = numpy.random.normal(150, 40, 100) / x train_x = x[:80] train_y = y[:80] test_x = x[80:] test_y = y[80:] plt.scatter(train_x, train_y) plt.show()
Hasil:
Hasilnya terlihat seperti kumpulan data asli, jadi ini adalah pilihan yang adil
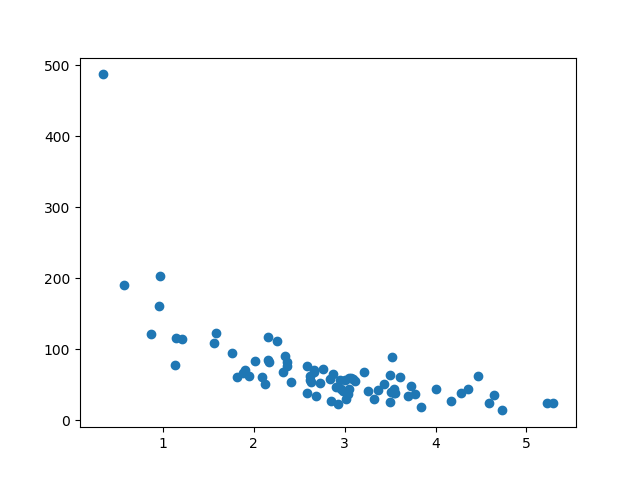
Tampilkan Testing Set
Untuk memastikan testing set tidak sepenuhnya berbeda, kita akan melihat testing set juga.
Contoh:
import numpy import matplotlib.pyplot as plt numpy.random.seed(2) x = numpy.random.normal(3, 1, 100) y = numpy.random.normal(150, 40, 100) / x train_x = x[:80] train_y = y[:80] test_x = x[80:] test_y = y[80:] plt.scatter(test_x, test_y) plt.show()
Hasil:
Testing set juga terlihat seperti kumpulan data asli
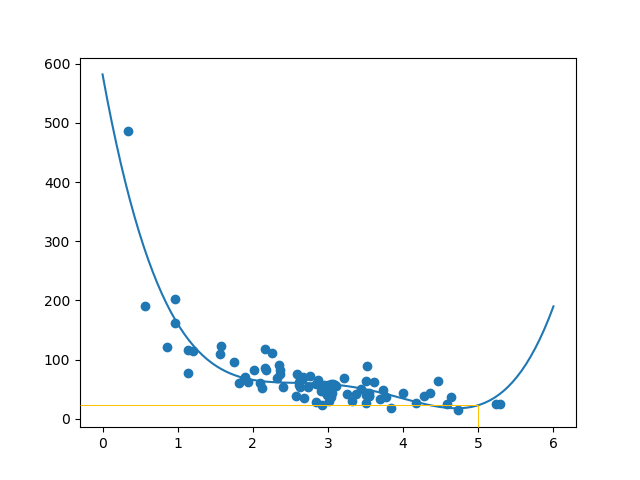
Fit Set Data
Seperti apa set data itu? Menurut pendapat saya yang paling cocok adalah regresi polinomial, jadi mari kita tarik garis regresi polinomial.
Untuk menggambar garis melalui titik data, kita akan menggunakan metode plot() dari modul matplotlib.
Contoh:
Gambarkan garis regresi polinomial melalui titik data
import numpy import matplotlib.pyplot as plt numpy.random.seed(2) x = numpy.random.normal(3, 1, 100) y = numpy.random.normal(150, 40, 100) / x train_x = x[:80] train_y = y[:80] test_x = x[80:] test_y = y[80:] mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 3)) myline = numpy.linspace(0, 6, 100) plt.scatter(train_x, train_y) plt.plot(myline, mymodel(myline)) plt.show()
Hasilnya:
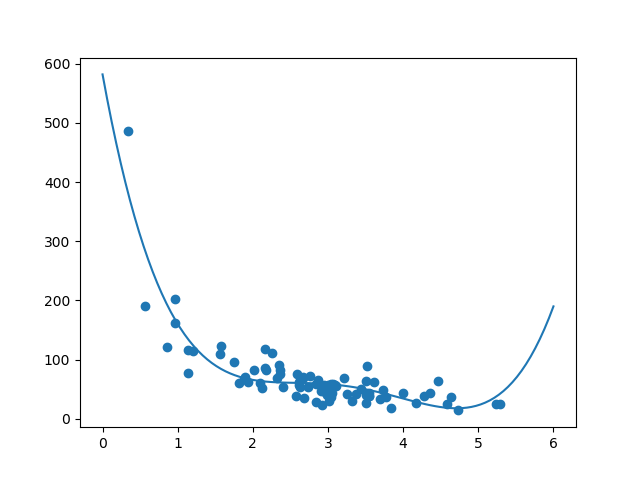
Hasilnya dapat mendukung saran saya tentang kumpulan data yang sesuai dengan regresi polinomial, meskipun itu akan memberi kita hasil yang aneh jika kita mencoba memprediksi nilai di luar set data. Contoh: garis tersebut menunjukkan bahwa pelanggan yang menghabiskan waktu 6 menit di toko akan melakukan pembelian senilai 200. Itu mungkin merupakan tanda overfitting.
Tapi bagaimana dengan skor R-squared? Skor R-squared adalah indikator yang baik untuk menilai seberapa baik set data tersebut sesuai dengan model.
R2
Ingat R2, juga dikenal sebagai R-squared.
R2 mengukur hubungan antara sumbu x dan sumbu y, dan nilainya berkisar dari 0 hingga 1, di mana 0 berarti tidak ada hubungan, dan 1 berarti terkait total.
Modul sklearn memiliki metode yang disebut r2_score() yang akan membantu kita menemukan hubungan ini.
Dalam hal ini, kami ingin mengukur hubungan antara menit ketika pelanggan berada di toko dan berapa banyak uang yang mereka belanjakan.
Contoh:
Seberapa cocok data testing tersebut dalam regresi polinomial
import numpy from sklearn.metrics import r2_score numpy.random.seed(2) x = numpy.random.normal(3, 1, 100) y = numpy.random.normal(150, 40, 100) / x train_x = x[:80] train_y = y[:80] test_x = x[80:] test_y = y[80:] mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4)) r2 = r2_score(train_y, mymodel(train_x)) print(r2)
Catatan: Hasil 0,799 menunjukkan hubungan yang baik.
Gunakan Testing Set
Sekarang kita telah membuat model yang baik, setidaknya dalam hal data training.
Sekarang kita ingin menguji model dengan data testing juga, untuk melihat apakah data tersebut memberi hasil yang sama.
Contoh:
Mari kita temukan skor R2 saat gunakan data testing
import numpy from sklearn.metrics import r2_score numpy.random.seed(2) x = numpy.random.normal(3, 1, 100) y = numpy.random.normal(150, 40, 100) / x train_x = x[:80] train_y = y[:80] test_x = x[80:] test_y = y[80:] mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4)) r2 = r2_score(test_y, mymodel(test_x)) print(r2)
Catatan: Hasil 0.809 menunjukkan bahwa model tersebut juga cocok dengan set pengujian, dan saya yakin bahwa kita dapat menggunakan model tersebut untuk memprediksi nilai di masa mendatang.
Prediksi Nilai
Sekarang kita telah menetapkan bahwa model yang kita buat sudah baik, selanjutnya kita dapat mulai memprediksi nilai baru.
Contoh:
Berapa banyak uang yang akan dihabiskan oleh seorang pembeli, jika dia tetap berada di toko selama 5 menit?
import numpy from sklearn.metrics import r2_score numpy.random.seed(2) x = numpy.random.normal(3, 1, 100) y = numpy.random.normal(150, 40, 100) / x train_x = x[:80] train_y = y[:80] test_x = x[80:] test_y = y[80:] mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4)) print(mymodel(5))
Contoh tersebut memperkirakan pelanggan menghabiskan 22,88 dolar, seperti yang terlihat pada diagram: