Traversing berarti melakukan perulangan atau berjalan melintasi node-tree.
Section Artikel
Travers Node Tree
Seringkali kita ingin mengulang dokumen XML, misalnya: saat kita ingin mengekstrak nilai setiap elemen. Hal ini disebut “Traversing the Node Tree”
Contoh di bawah ini mengulang melalui semua child node <book> dan menampilkan nama beserta nilainya:
Contoh :
<!DOCTYPE html> <html> <body> <p id="demo"></p> <script> var x, i, xmlDoc; var txt = ""; var text = "<book>" + "<title>Everyday Italian</title>" + "<author>Giada De Laurentiis</author>" + "<year>2005</year>" + "</book>"; parser = new DOMParser(); xmlDoc = parser.parseFromString(text,"text/xml"); // documentElement always represents the root node x = xmlDoc.documentElement.childNodes; for (i = 0; i < x.length ;i++) { txt += x[i].nodeName + ": " + x[i].childNodes[0].nodeValue + "<br>"; } document.getElementById("demo").innerHTML = txt; </script> </body> </html>
Output :

Penjelasan kode :
- Muat string XML ke xmlDoc
- Dapatkan child node dari elemen root
- Untuk setiap child node, keluarkan node name dan node value dari simpul teks
Perbedaan Browser dalam DOM Parsing
Semua browser modern mendukung spesifikasi DOM W3C.
Namun, ada beberapa perbedaan antar browser. Satu perbedaan penting adalah:
- Cara mereka menangani ruang putih dan garis baru
DOM – White Spaces dan New Lines
XML sering kali berisi baris baru atau karakter spasi kosong di antara node. Hal ini sering terjadi ketika dokumen diedit oleh editor sederhana seperti Notepad.
Contoh berikut (diedit oleh Notepad) berisi CR / LF (baris baru) antara setiap baris dan dua spasi di depan setiap child node:
<book> <title>Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book>
Internet Explorer 9 dan versi sebelumnya TIDAK memperlakukan spasi kosong atau baris baru sebagai node teks sementara browser lain melakukannya.
Contoh berikut akan menampilkan jumlah node turunan yang dimiliki elemen root (dari books.xml). IE9 dan sebelumnya akan mengeluarkan 4 child node, sedangkan IE10 dan versi yang lebih baru serta browser lain akan mengeluarkan 9 child node:
Contoh :
<!DOCTYPE html>
<html>
<body>
<p id="demo"></p>
<script>
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
myFunction(this);
}
};
xhttp.open("GET", "books.xml", true);
xhttp.send();
function myFunction(xml) {
var xmlDoc = xml.responseXML;
var x = xmlDoc.documentElement.childNodes;
document.getElementById("demo").innerHTML =
"Number of child nodes: " + x.length;
}
</script>
</body>
</html>
Output :
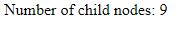
PCDATA – Data Karakter yang Diurai(parser)
Pengurai XML biasanya mengurai semua teks dalam dokumen XML.
Saat elemen XML diurai, teks di antara tag XML juga diurai:
<message>teks ini parsed</message>
Parser melakukan ini karena elemen XML bisa berisi elemen lain, seperti dalam contoh ini, di mana elemen <name> berisi dua elemen lain (pertama dan terakhir):
<name><first>Bill</first><last>Gates</last></name>
dan parser akan memecahnya menjadi sub-elemen seperti ini:
<name> <first>Bill</first> <last>Gates</last> </name>
Parsed Character Data (PCDATA) adalah istilah yang digunakan tentang data teks yang akan diurai(parsed) oleh XML parser.
CDATA – Data Karakter (Tidak Terurai)
Istilah CDATA digunakan untuk data teks yang tidak boleh diurai(parsed) oleh XML parser.
Karakter seperti “<” dan “&” ilegal dalam elemen XML.
“<” akan menghasilkan kesalahan karena parser menafsirkannya sebagai awal elemen baru.
“&” akan menghasilkan kesalahan karena parser menafsirkannya sebagai awal dari entitas karakter.
Beberapa teks, seperti kode JavaScript, mengandung banyak karakter “<” atau “&”. Untuk menghindari kesalahan, kode skrip dapat didefinisikan sebagai CDATA.
Semua yang ada di dalam bagian CDATA diabaikan oleh parser.
Bagian CDATA dimulai dengan “<![CDATA[” and ends with “]]>“:
<script>
<![CDATA[
function matchwo(a,b) {
if (a < b && a < 0) {
return 1;
} else {
return 0;
}
}
]]>
</script>Pada contoh di atas, semua yang ada di dalam bagian CDATA diabaikan oleh parser.
Catatan tentang bagian CDATA:
Bagian CDATA tidak boleh berisi string “]]>”. Bagian CDATA bertingkat tidak diperbolehkan.
“]]>” Yang menandai akhir bagian CDATA tidak boleh berisi spasi atau jeda baris.