Section Artikel
Pohon Keputusan
Dalam bab ini kita akan belajar bagaimana membuat “Pohon Keputusan”. Pohon Keputusan adalah Diagram Alir, yang dapat membantu kita membuat keputusan berdasarkan pengalaman sebelumnya.
Dalam contoh ini, seseorang akan mencoba memutuskan apakah dia harus pergi ke acara komedi atau tidak.
Berikut data yang sudah dibuat oleh seseorang setiap kali ada acara komedi di kota, dan mendaftarkan beberapa informasi tentang komedian, dan juga mendaftar apakah dia hadir atau tidak.
| Age | Experience | Rank | Nationality | Go |
| 36 | 10 | 9 | UK | NO |
| 42 | 12 | 4 | USA | NO |
| 23 | 4 | 6 | N | NO |
| 52 | 4 | 4 | USA | NO |
| 43 | 21 | 8 | USA | YES |
| 44 | 14 | 5 | UK | NO |
| 66 | 3 | 7 | N | YES |
| 35 | 14 | 9 | UK | YES |
| 52 | 13 | 7 | N | YES |
| 35 | 5 | 9 | N | YES |
| 24 | 3 | 5 | USA | NO |
| 18 | 3 | 7 | UK | YES |
| 45 | 9 | 9 | UK | YES |
Sekarang, berdasarkan kumpulan data ini, Python dapat membuat pohon keputusan yang dapat digunakan untuk memutuskan apakah ada acara baru yang layak untuk dihadiri.
Bagaimana cara kerjanya?
Pertama, impor modul yang dibutuhkan, dan baca kumpulan data dengan pandas.
Contoh:
Baca dan cetak kumpulan data
import pandas from sklearn import tree import pydotplus from sklearn.tree import DecisionTreeClassifier import matplotlib.pyplot as plt import matplotlib.image as pltimg df = pandas.read_csv("shows.csv") print(df)
Untuk membuat pohon keputusan, semua data harus berupa numerik.
Kita harus mengubah kolom non numerik ‘Nationality’ dan ‘Go’ menjadi nilai numerik.
Pandas memiliki metode map() yang mengambil library dengan informasi tentang cara mengonversi nilai.
{‘UK’: 0, ‘USA’: 1, ‘N’: 2}
Berarti mengonversi nilai ‘UK’ menjadi 0, ‘USA’ menjadi 1, dan ‘N’ menjadi 2.
Contoh:
Ubah nilai string menjadi nilai numerik
import pandas
from sklearn import tree
import pydotplus
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import matplotlib.image as pltimg
df = pandas.read_csv("shows.csv")
d = {'UK': 0, 'USA': 1, 'N': 2}
df['Nationality'] = df['Nationality'].map(d)
d = {'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
print(df)
Kemudian kita harus memisahkan kolom fitur dari kolom target.
Kolom fitur adalah kolom yang kita coba prediksi, dan kolom target adalah kolom dengan nilai yang kita coba prediksi.
Contoh:
X adalah kolom fitur, y adalah kolom target
import pandas
from sklearn import tree
import pydotplus
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import matplotlib.image as pltimg
df = pandas.read_csv("shows.csv")
d = {'UK': 0, 'USA': 1, 'N': 2}
df['Nationality'] = df['Nationality'].map(d)
d = {'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
features = ['Age', 'Experience', 'Rank', 'Nationality']
X = df[features]
y = df['Go']
print(X)
print(y)
Sekarang kita dapat membuat pohon keputusan yang sebenarnya, menyesuaikannya dengan detail tersebut, dan menyimpan file .png di komputer.
Contoh:
Buat Pohon Keputusan, simpan sebagai gambar, dan tunjukkan gambar
import pandas
from sklearn import tree
import pydotplus
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import matplotlib.image as pltimg
df = pandas.read_csv("shows.csv")
d = {'UK': 0, 'USA': 1, 'N': 2}
df['Nationality'] = df['Nationality'].map(d)
d = {'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
features = ['Age', 'Experience', 'Rank', 'Nationality']
X = df[features]
y = df['Go']
dtree = DecisionTreeClassifier()
dtree = dtree.fit(X, y)
data = tree.export_graphviz(dtree, out_file=None, feature_names=features)
graph = pydotplus.graph_from_dot_data(data)
graph.write_png('mydecisiontree.png')
img=pltimg.imread('mydecisiontree.png')
imgplot = plt.imshow(img)
plt.show()
Penjelasan Hasil
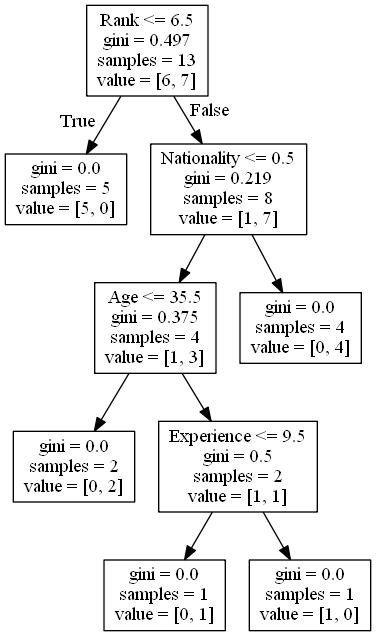
Pohon keputusan menggunakan keputusan kita yang sebelumnya untuk menghitung kemungkinan kita ingin pergi melihat komedian atau tidak.
Mari kita baca berbagai aspek pohon keputusan:

Rank
Rank <= 6,5 artinya setiap komedian dengan rank 6,5 atau lebih rendah akan mengikuti panah True (ke kiri), dan sisanya akan mengikuti panah False (ke kanan).
gini = 0,497 mengacu pada kualitas pemisahan, dan selalu berupa angka antara 0,0 dan 0,5, di mana 0,0 berarti semua sampel mendapatkan hasil yang sama, dan 0,5 berarti bahwa pemisahan dilakukan tepat di tengah.
sampel = 13 berarti masih ada 13 pelawak yang tersisa pada saat ini dalam keputusan, karena ini adalah langkah pertama.
value = [6, 7] artinya dari 13 komedian ini, 6 akan mendapatkan “NO”, dan 7 akan mendapatkan “GO”.
Gini
Ada banyak cara untuk membagi sampel, kita menggunakan metode GINI dalam tutorial ini.
Metode Gini menggunakan rumus ini:
Gini = 1 – (x / n) 2 – (y / n) 2
Di mana x adalah jumlah jawaban positif (“GO”), n adalah jumlah sampel, dan y adalah jumlah jawaban negatif (“NO”), yang memberikan kita perhitungan ini:
1 – (7/13) 2 – (6/13) 2 = 0,497
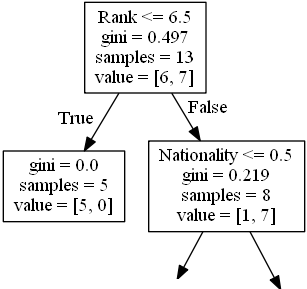
Langkah selanjutnya berisi dua kotak, satu kotak untuk komedian dengan ‘Rank’ 6,5 atau lebih rendah, dan satu kotak dengan sisanya.
True – 5 Komedian Berakhir Di Sini:
gini = 0.0 artinya semua sampel mendapatkan hasil yang sama.
sampel = 5 berarti masih ada 5 pelawak di cabang ini (5 pelawak dengan Rank 6,5 atau lebih rendah).
value = [5, 0] berarti 5 akan mendapatkan “NO” dan 0 akan mendapatkan “GO”.
False – 8 Komedian Lanjutkan:
Nationality
Nationality <= 0,5 artinya para pelawak dengan nilai kebangsaan kurang dari 0,5 akan mengikuti tanda panah ke kiri (yang berarti semua orang dari UK,), dan sisanya akan mengikuti tanda panah ke kanan.
gini = 0,219 berarti sekitar 22% sampel akan menuju satu arah.
sampel = 8 berarti masih ada 8 pelawak yang tersisa di cabang ini (8 pelawak dengan Rank lebih dari 6,5).
value = [1, 7] artinya dari 8 komedian ini, 1 akan mendapatkan “NO” dan 7 akan mendapatkan “GO”.
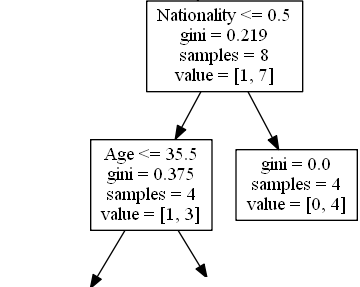
True – 4 Komedian Lanjutkan:
Age
Age <= 35,5 artinya komedian yang berumur 35,5 atau lebih muda akan mengikuti tanda panah ke kiri, dan sisanya akan mengikuti panah ke kanan.
gini = 0,375 artinya sekitar 37,5% sampel akan searah.
sample = 4 artinya masih ada 4 komedian yang tersisa di cabang ini (4 komedian dari UK).
value = [1, 3] artinya dari 4 komedian ini, 1 akan mendapatkan “NO” dan 3 akan mendapatkan “GO”.
False – 4 Komedian Berakhir Di Sini:
gini = 0.0 artinya semua sampel mendapatkan hasil yang sama.
sample = 4 artinya masih ada 4 komedian yang tersisa di cabang ini (4 komedian bukan dari Inggris).
value = [0, 4] artinya dari 4 komedian ini, 0 akan mendapatkan “NO” dan 4 akan mendapatkan “GO”.
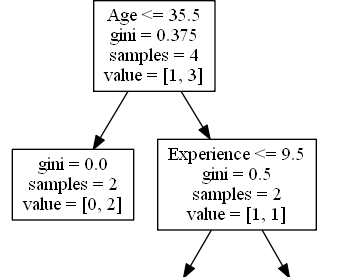
True – 2 Komedian Berakhir Di Sini:
gini = 0.0 artinya semua sampel mendapatkan hasil yang sama.
sampel = 2 berarti masih ada 2 pelawak di cabang ini (2 pelawak berusia 35,5 tahun atau lebih muda).
value = [0, 2] artinya dari 2 komedian ini, 0 akan mendapat “NO” dan 2 akan mendapat “GO”.
False – 2 Komedian Lanjutkan:
Experience
Experience <= 9,5 berarti komedian dengan pengalaman 9,5 tahun, atau lebih, akan mengikuti panah ke kiri, dan sisanya akan mengikuti panah ke kanan.
gini = 0,5 berarti 50% sampel akan menuju satu arah.
sampel = 2 berarti masih ada 2 komedian yang tersisa di cabang ini (2 komedian berusia di atas 35,5).
value = [1, 1] artinya dari 2 komedian ini, 1 akan mendapatkan “NO” dan 1 akan mendapatkan “GO”.
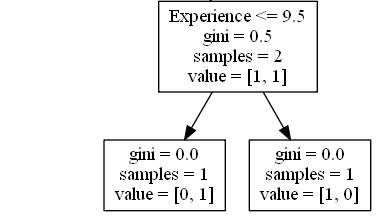
True – 1 Komedian Berakhir Di Sini:
gini = 0.0 artinya semua sampel mendapatkan hasil yang sama.
sample = 1 artinya masih ada 1 komedian yang tersisa di cabang ini (1 komedian dengan pengalaman 9,5 tahun atau kurang).
value = [0, 1] berarti 0 akan mendapatkan “NO” dan 1 akan mendapatkan “GO”.
Salah – 1 Komedian Berakhir Di Sini:
gini = 0.0 artinya semua sampel mendapatkan hasil yang sama.
sample = 1 artinya masih ada 1 komedian yang tersisa di cabang ini (1 komedian dengan pengalaman lebih dari 9,5 tahun).
value = [1, 0] berarti 1 akan mendapatkan “NO” dan 0 akan mendapatkan “GO”.
Prediksi Nilai
Kita dapat menggunakan Pohon Keputusan untuk memprediksi nilai baru.
Contoh: Haruskah saya menonton acara yang dibintangi komedian Amerika berusia 40 tahun, dengan pengalaman 10 tahun, dan peringkat komedi 7?
Contoh:
Gunakan metode predict() untuk memprediksi nilai baru
import pandas
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
df = pandas.read_csv("shows.csv")
d = {'UK': 0, 'USA': 1, 'N': 2}
df['Nationality'] = df['Nationality'].map(d)
d = {'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
features = ['Age', 'Experience', 'Rank', 'Nationality']
X = df[features]
y = df['Go']
dtree = DecisionTreeClassifier()
dtree = dtree.fit(X, y)
print(dtree.predict([[40, 10, 7, 1]]))
print("[1] means 'GO'")
print("[0] means 'NO'")
Contoh:
Apa jawabannya jika peringkat rank adalah 6?
import pandas
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
df = pandas.read_csv("shows.csv")
d = {'UK': 0, 'USA': 1, 'N': 2}
df['Nationality'] = df['Nationality'].map(d)
d = {'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
features = ['Age', 'Experience', 'Rank', 'Nationality']
X = df[features]
y = df['Go']
dtree = DecisionTreeClassifier()
dtree = dtree.fit(X, y)
print(dtree.predict([[40, 10, 6, 1]]))
print("[1] means 'GO'")
print("[0] means 'NO'")
Hasil Berbeda
Anda akan melihat bahwa Pohon Keputusan memberikan hasil yang berbeda jika Anda menjalankannya cukup sering, bahkan jika Anda memberinya data yang sama.
Itu karena Pohon Keputusan tidak memberi kita jawaban pasti 100%. Ini didasarkan pada kemungkinan hasil, dan jawabannya akan bervariasi.