Pernahkah Kita bertanya-tanya bagaimana hasilnya tercantum di halaman hasil mesin pencari? Algoritma atau teknik apa yang terlibat untuk mengekstrak konten terbaik dari triliunan halaman dan daftar dalam hasil pencarian? Teknik itu adalah web crawler. Web crawler mencari melalui web untuk hasil terbaik dan menyajikannya kepada Kita dalam format terindeks.
Teknologi yang sama berfungsi ketika Kita mengumpulkan informasi jejaring sosial pengguna, mengingat ID pengguna. Bahkan, Kita menemukan aplikasi web crawler dalam kehidupan sehari-hari Kita, apakah Kita memesan tiket pesawat atau mencari restoran vegetarian terbaik di lingkungan Kita.
Keberhasilan web crawler untuk mengindeks pencarian atau mengekstrak data telah menjadikannya sebagai tools populer bagi data scientists, search engine specialists, dan scraper untuk mengekstrak informasi yang berguna dari berbagai sumber online.
Seperti namanya, web crawler adalah program komputer atau skrip otomatis yang bekerja melalui World Wide Web dengan cara yang telah ditentukan dan metodologi untuk mengumpulkan data. Tools web crawler mengumpulkan detail tentang setiap halaman: judul, gambar, kata kunci, halaman tertaut lainnya, dan lain-lain. Ini secara otomatis memetakan web untuk mencari dokumen, situs web, umpan RSS, dan alamat email. Kemudian menyimpan dan mengindeks data ini.
Juga dikenal sebagai spider atau bot spider, program yang bekerja dengan cara seperti laba-laba merangkak dan bergerak dari satu situs web ke situs web lain, serta menangkap setiap situs web. Semua isi telah dibaca dan entri dibuat untuk indeks mesin pencari.
Web crawler mendapatkan namanya dari perilaku merangkaknya melalui situs web, satu halaman pada satu waktu, serta mendapatkan tautan ke halaman lain di situs sampai semua halaman telah dibaca.
Setiap mesin pencari menggunakan web crawler sendiri untuk mengumpulkan data dari internet dan mengindeks hasil pencarian. Misalnya, mesin pencari Google menggunakan Googlebot.
Web crawler mengunjungi situs web yang baru dan peta situs yang telah dikirimkan oleh pemiliknya dan secara berkala mengunjungi kembali situs untuk memeriksa pembaruan. Jadi, jika Kita mencari istilah “web crawler” di Google, hasil yang Kita dapatkan hari ini mungkin berbeda dari apa yang Kita dapatkan beberapa minggu yang lalu. Ini karena web crawler terus bekerja, mencari situs web yang relevan yang mendefinisikan atau menggambarkan “web crawler” dengan cara terbaik, memperhitungkan situs web baru, halaman web, atau konten yang diperbarui.
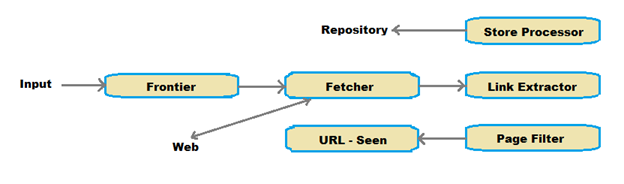
Web crawler “merangkak” melalui web untuk menemukan halaman situs web untuk dikunjungi, menggunakan beberapa algoritma untuk menilai konten atau kualitas tautan dalam indeksnya. Aturan ini menentukan perilaku pendataannya: situs mana yang akan di-crawl, seberapa sering meng-crawl ulang halaman, berapa banyak halaman di situs yang akan diindeks, dan sebagainya. Ketika mengunjungi situs web baru, lalu mengunduh robot.txt yaitu protokol “standar pengecualian robot” yang dirancang untuk membatasi akses tak terbatas oleh tools web crawler. File berisi informasi peta situs (URL untuk di-crawl) dan aturan pencarian (halaman mana yang akan di-crawl dan bagian mana yang harus diabaikan).
Crawler melacak setiap link, baik internal maupun eksternal untuk ditambahkan ke halaman berikutnya yang dikunjungi. Proses ini diulang sampai crawler mendarat di halaman tanpa tautan lagi atau mengalami kesalahan seperti 404 dan 403 untuk memuat konten situs ke dalam database dan indeks mesin pencari. Ini adalah database besar berisi kata-kata dan frasa yang ditemukan di setiap halaman, dan juga menentukan di mana kata-kata terjadi di halaman web yang berbeda. Saat fungsi pencarian dan kueri digunakan, itu membantu end user untuk menemukan halaman web dengan kata atau frasa yang dimasukkan.
Pengindeksan adalah fungsi penting dari mesin pencari web crawler. Algoritma menafsirkan tautan dan nilainya dalam indeks untuk memberikan hasil pencarian yang relevan.
Ketika Kita mencari kata atau frasa tertentu, mesin pencari akan mempertimbangkan ratusan faktor untuk memilih dan menyajikan halaman web terindeks kepada Kita.
Contoh faktor yang dipertimbangkan adalah :
Sebagian besar mesin pencari memiliki beberapa web crawler yang bekerja pada saat yang sama dari server yang berbeda. Proses dimulai dengan daftar alamat web dari crawl sebelumnya dan peta situs yang disediakan oleh pemilik situs web. Saat crawler mengunjungi situs web, tautan yang ditemukan di situs tersebut digunakan untuk menemukan halaman lain. Jadi sekarang Kita tahu mengapa administrator SEO situs web suka menggunakan backlink! Backlink ke situs web Kita adalah sinyal untuk mesin pencari yang dijamin orang lain untuk konten Kita.
Google pertama kali mulai menggunakan web crawler untuk mencari dan mengindeks konten sebagai cara termudah untuk menemukan situs web berdasarkan kata kunci dan frasa. Popularitas dan beragam aplikasi hasil pencarian terindeks akhirnya berkembang untuk dimonetisasi.
Mesin pencari dan sistem TI membuat web crawler mereka sendiri yang diprogram dengan algoritma yang berbeda. Proses ini meliputi merangkak di web, memindai konten, dan membuat salinan halaman yang dikunjungi untuk pengindeksan berikutnya. Hasilnya terlihat, karena hari ini Kita dapat menemukan informasi atau data apa pun yang ada di web.
Kita dapat menggunakan crawler untuk mengumpulkan jenis informasi tertentu dari halaman web, seperti :
Penggunaan web crawler di bidang kecerdasan bisnis meliputi :
{kind=link}