Section Artikel
Pengertian Algoritma K-Means
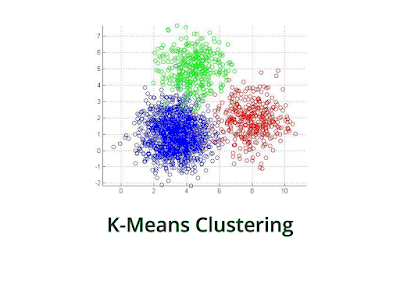
Algoritma K-Means adalah salah satu algoritma dalam analisis clustering yang digunakan untuk mengelompokkan data ke dalam kategori yang berbeda secara otomatis. Tujuan algoritma ini adalah untuk mempartisi himpunan data ke dalam kelompok-kelompok (klaster) yang berbeda berdasarkan kemiripan antar data.
Selain itu, tujuan lain dari algoritma K-Means adalah untuk meminimalkan nilai fungsi inersia sehingga klaster-klaster yang dihasilkan memiliki kompak dan terpisah dengan jelas.
Algoritma K-Means mengasumsikan bahwa klaster-klaster yang dihasilkan akan memiliki bentuk geometris yang terdefinisi dengan baik dan jarak antara titik data yang ada dengan pusat klaster akan minimal.
Algoritma K-Means memiliki beberapa kelemahan, seperti sensitivitas terhadap inisialisasi titik pusat klaster awal, hasil yang mungkin berbeda-beda pada setiap run, serta keterbatasan dalam menangani data dengan bentuk klaster yang kompleks atau ukuran klaster yang tidak seimbang.
Algoritma K-Means adalah algoritma clustering yang digunakan untuk mempartisi himpunan data menjadi beberapa kelompok (klaster) berdasarkan kesamaan atributnya.
Algoritma ini dapat mengelompokkan data ke dalam klaster sehingga data dalam satu klaster memiliki kesamaan yang tinggi dan data antar klaster memiliki perbedaan yang signifikan.
Algoritma K-Means mencoba untuk mengoptimalkan fungsi tujuan yang disebut sebagai fungsi inersia (inertia function) atau sum squared error (SSE). Fungsi tersebut mengukur sejauh mana data dalam klaster berada dekat dengan pusat klasternya.
Fungsi Algoritma K-Means
Fungsi algoritma K-Means adalah untuk mengelompokkan data ke dalam klaster berdasarkan kesamaan atributnya. Tujuan dari algoritma ini adalah meminimalkan jarak antara data dengan pusat klaster.
Dengan tujuan tersebut maka data dalam satu klaster memiliki kesamaan yang tinggi dan data antar klaster memiliki perbedaan yang signifikan.Tujuan utama algoritma K-Means adalah untuk meminimalkan nilai fungsi inersia ini.
Dalam langkah-langkah iterasi, algoritma K-Means berusaha untuk memindahkan data ke klaster yang memiliki pusat klaster terdekat sehingga mengurangi nilai fungsi inersia. Algoritma ini terus diulang hingga konvergensi, di mana penempatan data tidak berubah secara signifikan atau mencapai kondisi berhenti yang ditentukan sebelumnya
Fungsi inersia (inertia function) atau sum squared error (SSE) digunakan sebagai fungsi tujuan dalam algoritma K-Means. Fungsi inersia mengukur sejauh mana data dalam klaster berada dekat dengan pusat klasternya.
Cara Kerja Algoritma K-means
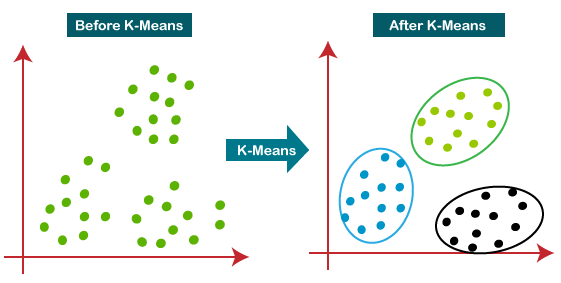
Berikut adalah cara kerja algoritma K-Means:
- Pertama-tama tentukan jumlah klaster yang diinginkan (K) dan acak pilih K titik sebagai titik pusat awal klaster (centroid). Posisi awal pusat klaster dapat dipilih secara acak atau menggunakan metode inisialisasi khusus.
- Kedua, hitung jarak antara setiap data dengan setiap titik pusat klaster. Pada langkah ini, data akan ditempatkan pada klaster yang memiliki pusat terdekat dengan data tersebut. Biasanya, jarak Euclidean digunakan sebagai metrik jarak antara data dan pusat klaster.
- Setelah semua data ditempatkan pada klaster, hitung kembali pusat klaster baru dengan mengambil rata-rata dari semua data dalam klaster tersebut. Pusat klaster baru ini akan menjadi titik pusat baru untuk iterasi selanjutnya.
- Ulangi langkah 2 dan 3 secara berulang sampai tidak ada perubahan dalam penempatan data pada klaster atau mencapai kondisi berhenti yang ditentukan sebelumnya. Dalam setiap iterasi, data akan ditempatkan kembali pada klaster yang sesuai berdasarkan perhitungan jarak terbaru, dan pusat klaster akan diperbarui.
- Setelah iterasi berhenti, algoritma K-Means menghasilkan partisi data ke dalam K klaster yang berbeda. Setiap data akan tergabung dalam satu klaster berdasarkan kesamaan atributnya dengan data-data lain dalam klaster yang sama.
Syarat-Syarat dalam Menerapkan Algoritma K-Means
Adapun beberapa syarat yang harus dipenuhi dalam penerapan algoritma K-Means:
- Jumlah klaster (K) harus ditentukan sebelumnya, algoritma K-Means membutuhkan jumlah klaster yang diinginkan sebagai parameter masukan. Jumlah klaster harus ditentukan sebelum menjalankan algoritma.
- Algoritma K-Means dirancang untuk mengelompokkan data numerik atau kontinu. Algoritma ini menggunakan matrik jarak, seperti jarak Euclidean, untuk menghitung kesamaan antara data point.
- K-Means mengasumsikan bahwa semua atribut memiliki skala yang seragam. Ketidakseragaman skala dapat menyebabkan atribut dengan skala besar memiliki pengaruh yang lebih besar pada perhitungan jarak daripada atribut dengan skala kecil.
- Data tidak terlalu besar, karena algoritma ini memerlukan perhitungan jarak untuk setiap data point dengan setiap titik pusat klaster, kompleksitas waktu algoritma meningkat seiring dengan jumlah data point.
- Bentuk klaster yang mirip dengan bola dan ukuran yang serupa, algoritma K-Means mengasumsikan bahwa klaster-klaster memiliki bentuk yang mirip dengan bola dan ukuran yang serupa.
- Tidak ada outlier yang signifikan, K-Means sangat sensitif terhadap adanya outlier dalam data. Outlier dapat mempengaruhi perhitungan pusat klaster dan menghasilkan partisi yang tidak akurat.
Kelebihan Algoritma K-Means
Berikut terdapat beberapa kelebihan yang ada pada algoritma K-Means.
- Algoritma K-Means relatif sederhana dan mudah dipahami. Konsepnya intuitif dan tidak memerlukan pengetahuan matematika atau statistik yang mendalam untuk mengimplementasikannya.
- Algoritma K-Means mampu mengelola dataset dengan jumlah data yang besar dengan efisien. Kompleksitas waktunya berbanding linear dengan jumlah data, sehingga lebih mudah diterapkan pada dataset yang besar.
- K-Means cenderung efisien dalam mengelola dataset dengan dimensi yang tinggi. Meskipun dimensi yang tinggi dapat mempengaruhi kinerja algoritma, K-Means masih mampu memberikan hasil yang dapat diterima dalam dimensi yang cukup tinggi.
- K-Means dapat ditingkatkan dengan menggunakan teknik paralel atau algoritma yang dioptimalkan untuk mengatasi masalah skalabilitas. Ini memungkinkan penggunaan K-Means pada dataset yang semakin besar.
- Hasil dari algoritma K-Means mudah diinterpretasikan. Setiap klaster memiliki pusat klaster yang mewakili kelompok data dalam klaster tersebut. Ini memungkinkan pemahaman yang lebih baik tentang struktur data dan kemiripannya di antara klaster-klaster.
- K-Means dapat diterapkan pada berbagai jenis data dan masalah clustering. Ini tidak terbatas pada jenis data tertentu atau domain tertentu, sehingga dapat digunakan dalam berbagai aplikasi dan bidang.
- Dalam banyak kasus, algoritma K-Means mencapai konvergensi yang cepat. Ini berarti algoritma tersebut cenderung memberikan hasil yang baik dalam waktu yang relatif singkat.
- K-Means dapat membantu mengenali pola dan hubungan antar data. Dengan mengelompokkan data ke dalam klaster, pola atau karakteristik yang serupa dapat ditemukan dalam klaster yang sama.
Kekurangan Algoritma K-Means
Berikut terdapat beberapa kekurangan dalam penggunaan algoritma K-Means:
- Algoritma K-Means sangat sensitif terhadap inisialisasi awal titik pusat klaster. Untuk mengatasi masalah ini, sering kali dilakukan beberapa percobaan dengan inisialisasi yang berbeda.
- Algoritma K-Means membutuhkan jumlah klaster yang diinginkan (K) sebagai parameter masukan. Pemilihan jumlah klaster yang salah dapat menghasilkan partisi yang tidak memadai atau tidak relevan.
- K-Means mengasumsikan bahwa klaster-klaster memiliki bentuk yang mirip dengan bola dan ukuran yang serupa. Oleh karena itu, algoritma ini tidak efektif untuk mengatasi klaster yang memiliki bentuk yang kompleks, seperti klaster yang berbentuk tidak teratur, elips, atau klaster dengan ukuran yang sangat berbeda-beda.
- K-Means sangat sensitif terhadap adanya outlier dalam data. Algoritma K-Means mungkin tidak mengenali outlier sebagai kelompok terpisah dan cenderung mengintegrasikan mereka ke dalam klaster yang ada.
- Ketika data memiliki dimensi yang tinggi, perhitungan jarak Euclidean yang digunakan dalam algoritma K-Means dapat menjadi tidak efektif. Konsep jarak yang bermakna dalam dimensi yang tinggi menjadi kabur dan dapat menghasilkan partisi yang tidak optimal.
- Algoritma K-Means dapat menghasilkan solusi yang berbeda-beda pada setiap run, terutama ketika terdapat titik pusat klaster yang sama atau jarak antara data yang sama. Ini dapat membuat interpretasi hasil yang sulit dan mengharuskan percobaan ulang dengan inisialisasi yang berbeda.
- K-Means cenderung menghasilkan klaster-klaster yang memiliki ukuran yang seimbang. Jika ada perbedaan yang signifikan dalam jumlah data antara klaster, algoritma ini mungkin tidak mampu menghasilkan partisi yang memadai.
- K-Means memerlukan skala yang seragam antara atribut-atribut yang digunakan. Jika atribut memiliki skala yang berbeda, atribut dengan skala besar akan memiliki pengaruh yang lebih besar pada perhitungan jarak dan dapat mendominasi dalam pembentukan klaster.
Permasalahan dalam K-Means
Berikut terdapat beberapa permasalahan yang dapat terjadi dalam penggunaan algoritma K-Means:
- Algoritma K-Means cenderung terjebak dalam solusi lokal yang suboptimal. Hal ini terjadi karena algoritma tersebut sangat sensitif terhadap inisialisasi awal titik pusat klaster. Jika inisialisasi awal yang buruk dilakukan, algoritma dapat menghasilkan partisi yang tidak optimal.
- K-Means mengasumsikan bahwa klaster-klaster memiliki bentuk yang mirip dengan bola dan ukuran yang serupa. Oleh karena itu, algoritma ini dapat menghadapi kesulitan dalam mengatasi klaster dengan bentuk yang kompleks atau tidak teratur, seperti klaster yang berbentuk tidak teratur, elips, atau memiliki ukuran yang sangat berbeda-beda.
- K-Means sangat sensitif terhadap adanya outlier dalam data. Outlier dapat mempengaruhi perhitungan pusat klaster dan menghasilkan partisi yang tidak akurat. Algoritma K-Means mungkin tidak mengenali outlier sebagai kelompok terpisah dan cenderung mengintegrasikan mereka ke dalam klaster yang ada.
- Algoritma K-Means membutuhkan jumlah klaster yang diinginkan (K) sebagai parameter masukan. Namun, dalam beberapa kasus, jumlah klaster yang tepat mungkin tidak diketahui sebelumnya. Pemilihan jumlah klaster yang salah dapat menghasilkan partisi yang tidak memadai atau tidak relevan.
- Ketika data memiliki dimensi yang tinggi, algoritma K-Means dapat menghadapi masalah. Dalam dimensi yang tinggi, perhitungan jarak Euclidean menjadi tidak efektif dan konsep jarak yang bermakna dapat menjadi kabur. Ini dapat menghasilkan partisi yang tidak optimal.
- K-Means cenderung menghasilkan klaster-klaster yang memiliki ukuran yang seimbang. Jika ada perbedaan yang signifikan dalam jumlah data antara klaster, algoritma ini mungkin tidak mampu menghasilkan partisi yang memadai.
- K-Means memerlukan skala yang seragam antara atribut-atribut yang digunakan. Jika atribut memiliki skala yang berbeda, atribut dengan skala besar akan memiliki pengaruh yang lebih besar pada perhitungan jarak dan dapat mendominasi dalam pembentukan klaster.
Contoh Algoritma K-Means
Berikut adalah beberapa penerapan dari K-means clusterin:
- Analisis klaster
- Segmentasi citra
- Kuantisasi vektor
- Kompresi gambar
- Kompresi gambar
- Segmentasi pasar
- Segmentasi gambar
- Segmentasi pelanggan
- Pengelompokan aset IT
- Pengelompokan dokumen
- Deteksi penipuan asuransi
- Mengidentifikasi data kanker
- Analisis data angkutan umum
- Segmentasi berita-berita online
- Klasifikasi citra penginderaan jauh
- Identifikasi daerah rawan kejahatan
- Menentukan Parameter Jumlah data, Cluster, dan Atribut dalam penjurusan Siswa